DeepLTL
Learning to Efficiently Satisfy Complex LTL Specifications for Multi-Task RL
ICLR 2025 (Oral)
ICLR 2025 (Oral)
💡TL;DR: We develop a novel approach to train RL agents to zero-shot follow arbitrary instructions specified in a formal language.
Linear temporal logic (LTL) has recently been adopted as a powerful formalism for specifying complex, temporally extended tasks in multi-task reinforcement learning (RL). However, learning policies that efficiently satisfy arbitrary specifications not observed during training remains a challenging problem. Existing approaches suffer from several shortcomings: they are often only applicable to finite-horizon fragments of LTL, are restricted to suboptimal solutions, and do not adequately handle safety constraints. In this work, we propose a novel learning approach to address these concerns. Our method leverages the structure of Büchi automata, which explicitly represent the semantics of LTL specifications, to learn policies conditioned on sequences of truth assignments that lead to satisfying the desired formulae. Experiments in a variety of discrete and continuous domains demonstrate that our approach is able to zero-shot satisfy a wide range of finite- and infinite-horizon specifications, and outperforms existing methods in terms of both satisfaction probability and efficiency.
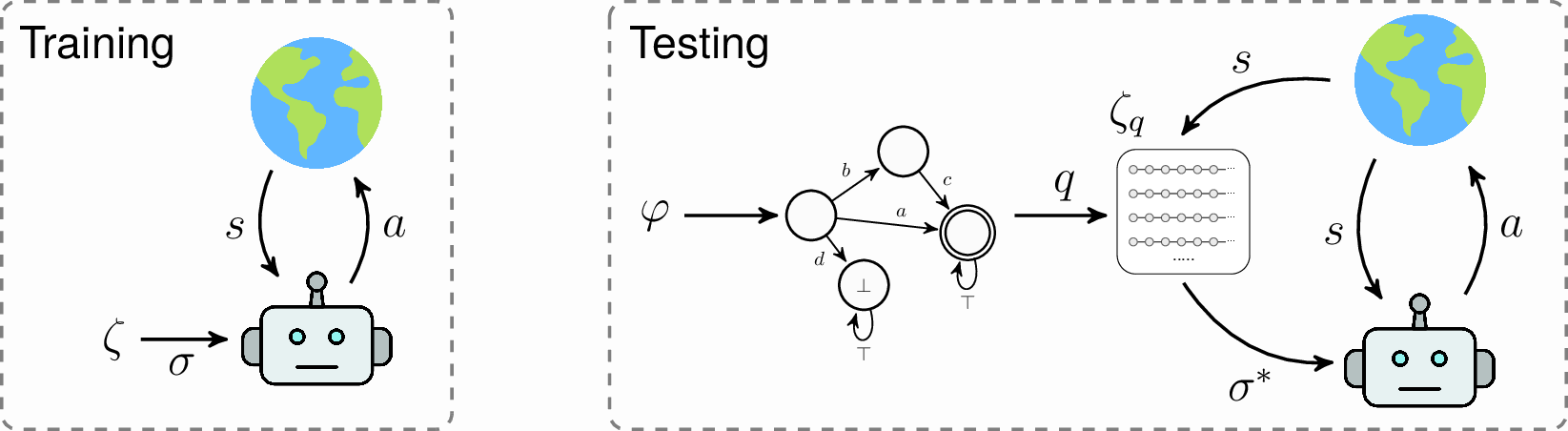
We develop a novel approach, called DeepLTL, to learn policies that efficiently zero-shot satisfy complex LTL specifications. We first employ goal-conditioned RL to learn a general policy that can execute reach-avoid sequences of high-level propositions, such as "reach goal A while avoiding region B, and subsequently stay in region C". At test time, we first translate a given LTL specification into a limit-deterministic Büchi automaton (LDBA), from which we extract possible reach-avoid sequences that satisfy the formula. We select the optimal sequence according to the learned value function, and execute it with the trained policy.
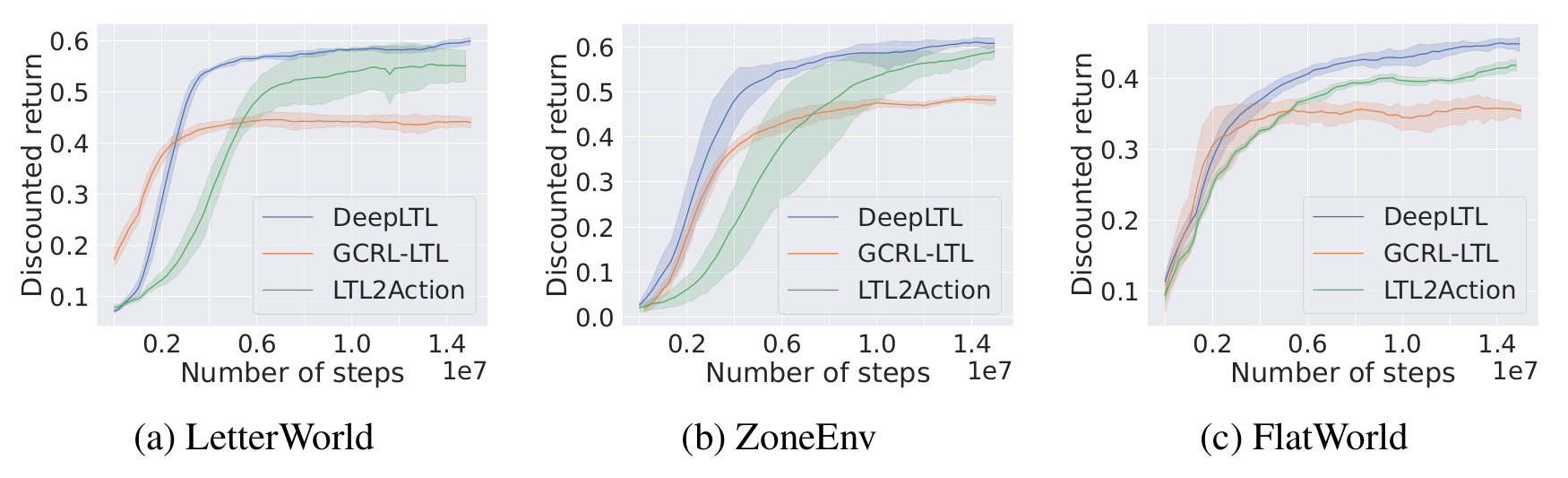
We find that DeepLTL is able to efficiently zero-shot satisfy a wide range of finite- and infinite-horizon LTL specifications in a variety of discrete and continuous domains. Our approach outperforms existing methods in terms of both satisfaction probability and efficiency.
\((\neg(\mathsf{yellow}\lor \mathsf{green})\;\mathsf{U}\; \mathsf{magenta}) \land \mathsf{F}\,\mathsf{blue}\)
\(\mathsf{G}\mathsf{F}\,\mathsf{green} \land \mathsf{G}\mathsf{F}\,\mathsf{yellow} \land \mathsf{G}\,\neg\mathsf{blue}\)
We demonstrate the behaviour of the task-conditioned policy learned by DeepLTL in the zone environment. DeepLTL consistently achieves the desired behaviour, even with complex, infinite-horizon specifications.
@inproceedings{deepltl,
title = {Deep{LTL}: Learning to Efficiently Satisfy Complex {LTL} Specifications for Multi-Task {RL}},
author = {Mathias Jackermeier and Alessandro Abate},
booktitle = {International Conference on Learning Representations ({ICLR})},
year = {2025}
}